Omni Interface Document (OID) Handler
|
Topics: |
The OID Handler is the primary processing engine of the Omni-Patient Server. It is the conduit through which data is loaded in the Enterprise Master Information Repository (EMIR).
Omni Interface Documents (OIDs) are the primary means by which Source Instances are loaded into the EMIR through the Omni-Patient Server. These eXtensible Markup Language (XML) interface documents, implement an XML Schema Definition (.xsd) called an Interface Document Specification (IDS). For more information, see Anatomy of Omni Interface Documents.
As a precursor to a deeper dive into the OID Handler, it is necessary to understand the various states of a Source Instance, since these will drive different processing paths.
The state of a Source Instance record is stored in the OmniStatus data element.
- ACTIVE. The default state.
- Records are visible in Management Central
- Records are eligible for consideration by the Matching Engine
- Records are available for consumption by downstream applications and analytics.
- INACTIVE. Considered a soft-delete from the system.
- Records are not visible in Management Central.
- Records are not eligible for consideration by the Matching Engine.
- Records are not available for consumption by downstream applications and analytics.
- Records remain in the EMIR.
- DELETE. Marks the record for hard-delete from
the system.
- Records are not visible in Management Central.
- Records are not eligible for consideration by the Matching Engine.
- Records are not available for consumption by downstream applications and analytics on ACTIVE records.
- Records remain in the EMIR until processed by the Delete Handler.
With a basic understanding of the OmniStatus for Source Instance records, it is possible to explore a more detailed view of the functionality of the OID Handler, as illustrated in the following diagram:
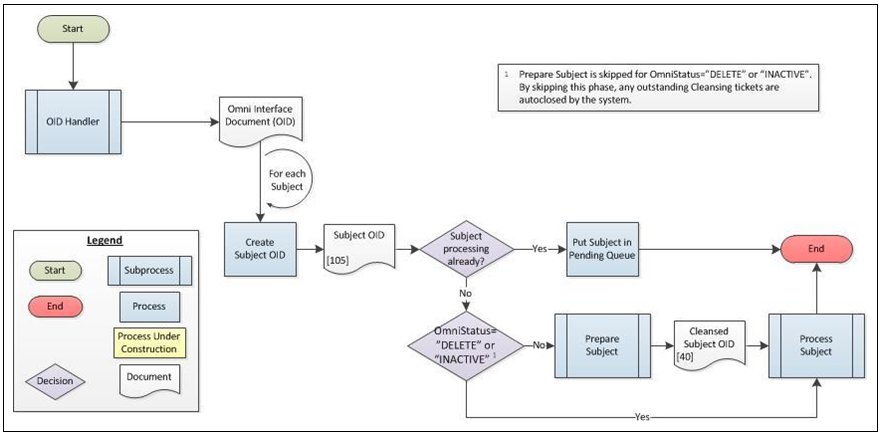
Since OmniInterface supports the ability to submit multiple subjects in a single payload, the OID must be split to define a Subject-level OID for each instance. To eliminate possible race conditions or database locks, the system also ensures that no more than one version of the same instance is processing at any one time.
If the Subject OID happens to currently be processing through the engine, it is temporarily placed into a Pending Queue for subsequent processing. For "ACTIVE" records that do not go to the Pending Queue, the values submitted by the source will be validated, standardized, and cleansed during the Prepare Subject subprocess, as configured for each specific implementation.
If any issues are identified through the preparation of the document, a case will be created for the Subject Instance, and any necessary remediation tickets will be communicated to the Advanced Remediation engine for follow-up.
Since the point of an OmniStatus of "DELETE" or "INACTIVE" is to physically or logically remove the record from the system, it is not necessary to execute the Prepare Subject subprocess. The side effect of skipping this phase is that no cleansing remediation tickets will be created, and any outstanding tickets from the previous version of the document will be automatically closed by the system.
The pending queue will be evaluated upon completion of the Process Subject subprocess, to determine if any records are now eligible for further processing.
Prepare Subject
|
Topics: |
The goal of preparing the subject is to enrich the document with the information that is required for mastering and persistence to the EMIR, as well as consumption by downstream applications or analytics.
The key features of the Prepare Subject subprocess will subsequently be discussed in further detail, but are listed as follows:
- OID Enhancement. Depending on the processing policy of the Subject, the document being processed will either replace the existing Subject, or will apply any updated data to the most recently processed complete Subject OID.
- Code Standardization. Converts code values from the various source systems to a standardized value set for use in Cleanse, Match, and Merge processes.
- Cleanse. Formats, validates, and standardizes values supplied from the source system.
The following diagram illustrates the process flow that is followed by the Prepare Subject subprocess.

OID Enhancement
The Omni-Patient Server is constructed to support standard CRUD (Create, Read, Update, Delete) operations. The initial enforcement of Create and Update policies are managed during the OID Enhancement subprocess, as shown in the following image.
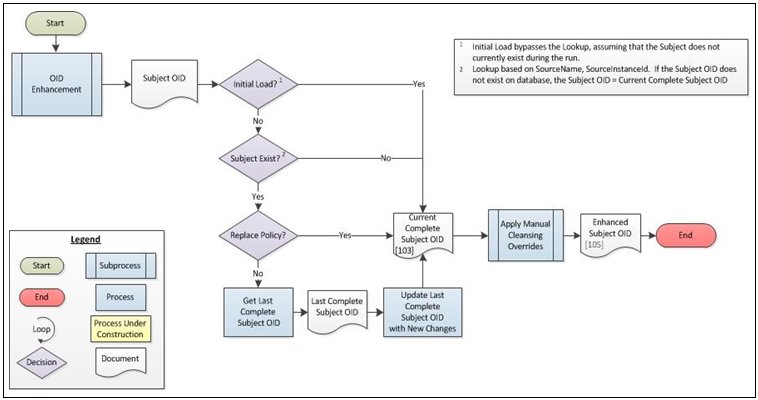
During Initial Load of the system (as configured through a system property), it is assumed that all records will be Creates. That being the case, the system bypasses the document lookup and update, and effectively recognizes the submitted document as the complete document.
Note: During Initial Load, it is considered a system error if more than one instance of each unique Subject OID is submitted.
Beyond Initial Load, update operations are managed through a Policy configuration, which allows the record to be updated in whole or in part. The following Policy values may be specified globally, at the Source level, at the Subject level, or by Subject within Source:
- Replace. Takes the document as is, deleting any unspecified nodes from the prior version of the OID.
- Merge. Updates the most recent version of the OID with only those updates specified in the new document.
When the integrator configures a Replace policy, the document is taken as is for further processing, and data sent previously for the subject will be deleted.
The system may also be configured to accept updates in whole or in part, allowing a trading partner to send an update to even a single field under a Merge policy. When this type of update is provided, it is necessary to apply the latest changes to the last known Complete Subject OID in order to create the most current representation of the Subject.
As a final step to the OID Enhancement subprocess, Manual Cleansing Overrides (MCOs) are applied to the document. These overrides can be entered by a data steward in Omni Patient Management Central (OPMC) in response to a remediation ticket, and are simply a replacement for values submitted (or omitted) by the trading partner.
Code Standardization
The Code Standardization subprocess is an extremely important step in Omni-Patient processing. The Cleanse, Match, and Merge rules, as well as Business Intelligence applications, require that the disparate values across Source Systems for the same data element concept (for example, Gender), be mapped into a single set of standard enumerated values.
Note: The Omni-Patient Server facilitates this process by providing the SourceCodeSet Interface Document Specification (IDS) to allow the integrator to pre-load these Source specific mapping.
The following is an example of a Code Standardization process.
|
Source |
Source CodeSet |
Source Code |
Source |
Standardized SourceCodeSet |
Standardized Code |
Standardized Description |
|---|---|---|---|---|---|---|
|
CPSI |
Gender |
1 |
Omni |
AdministrativeSex |
F |
Female |
|
Cerner |
Sex |
f |
Omni |
AdministrativeSex |
F |
Female |
|
Allscripts |
GenderCode |
Female |
Omni |
AdministrativeSex |
F |
Female |
|
CPSI |
Gender |
2 |
Omni |
AdministrativeSex |
F |
Male |
|
Cerner |
Sex |
M |
Omni |
AdministrativeSex |
F |
Male |
|
Allscripts |
GenderCode |
Male |
Omni |
AdministrativeSex |
F |
Male |
Once preloaded, these SourceCodeSet and SourceCode values are used to validate codes that are submitted on Mastered or Transactional Subjects. The following process flow describes how these validation rules are applied to prepare the document for later use by the cleansing and matching services.
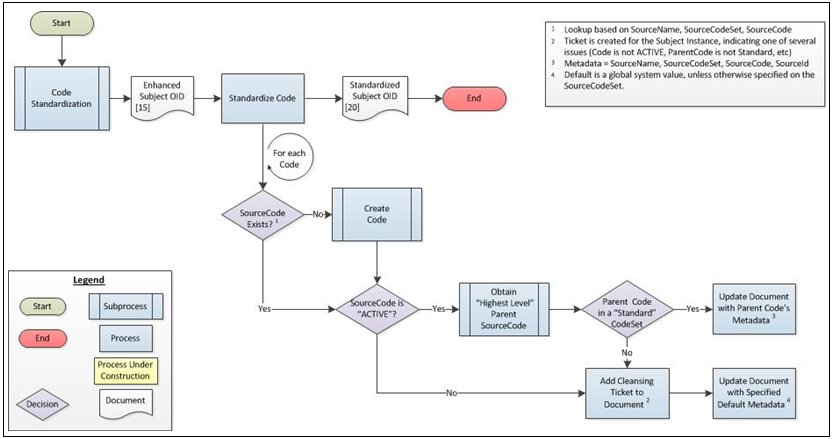
Although new code values may be created for a given SourceCodeSet during Subject OID processing, they are never mapped to the Standardized set, since it is impossible for the system to know this information.
Data Stewards are notified of this condition through Remediation Tickets, and may use Omni-Patient Management Central (OPMC) to help remediate the issue.
Create Code
When new code values are encountered during the processing of a subject, it may be necessary to create the code, and even the SourceCodeSet, if they do not currently exist in the system.
Omni-Patient uses two parameters of the SourceCodeSet (AllowCreate and StandardSet) to determine the status with which the code will be created, as well as whether remediation tickets are required, as shown in the following image.
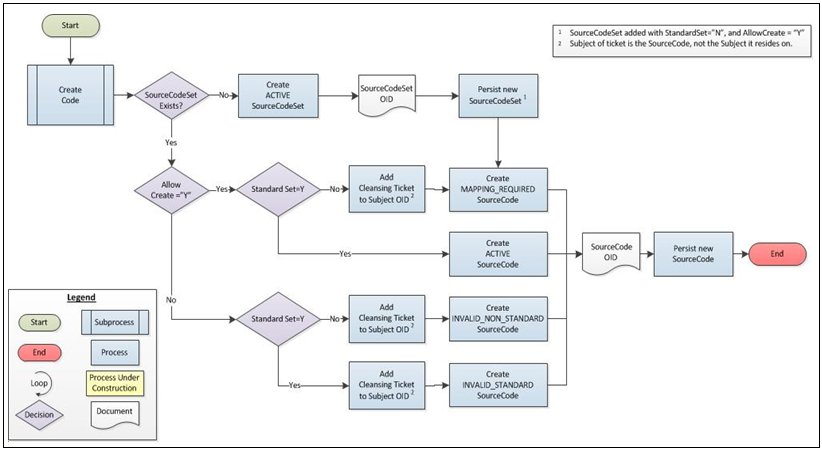
The following table illustrates the status with which the resulting SourceCode will be created, given the AllowCreate and StandardSet parameters on its SourceCodeSet.
|
SourceCodeSet AllowCreate? |
SourceCodeSet StandardSet? |
Resulting Source Code Status |
Remediation Ticket? |
Business Scenario |
|---|---|---|---|---|
|
Yes |
No |
MAPPING_REQUIRED |
Yes |
A new code has been added that requires mapping to a SourceCodeSet with StandardSet=Y. |
|
Yes |
Yes |
ACTIVE |
No |
An active code that may be used immediately. |
|
No |
No |
INVALID_NON_STANDARD |
Yes |
An attempt was made to add a new value to a CodeSet that does not allow creation. This will need to be remediated at the source (either through changing the value in the Subject or updating the SourceCodeSet. |
|
No |
Yes |
INVALID_STANDARD |
Yes |
An attempt was made to add a new value to a CodeSet that does not allow creation. This will either need to be remediated at the source by changing the value in the Subject or mapping the code to a SourceCodeSet with StandardSet=Y. |
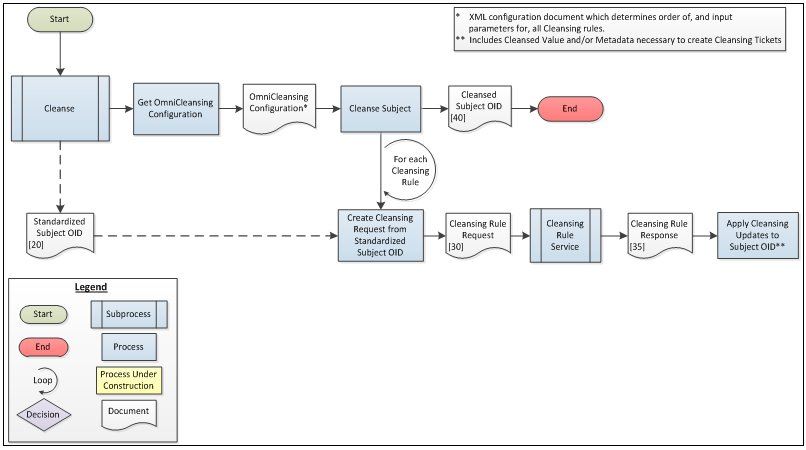
Cleanse
The Cleanse subprocess interacts with the iWay Data Quality Suite by calling a set of customer-configured rules that help to ensure the accuracy, consistency, and completeness of the data that will reside in the EMIR.
Cleansed values and any other resulting metadata required to generate a ticket within a case in the Advanced Remediation tool are applied to the Cleansed Subject OID. At the end of the Cleanse process, the Subject OID is fully prepared and ready for further processing.
The following diagram illustrates the process flow that is followed by the Cleanse subprocess.
Process Subject
|
Topics: |
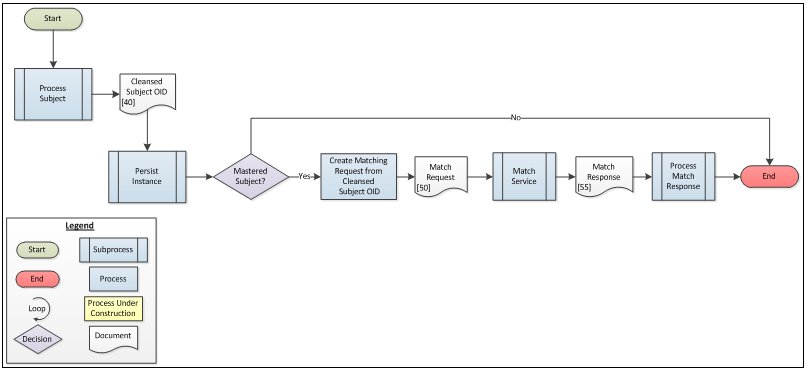
Once the document has been prepared, it is now ready for processing and persistence to the Enterprise Mastered Information Repository (EMIR).
All Subjects will attempt to persist the cleansed Subject Instance that results from the Prepare Subject subprocess. Mastered subjects (such as Patient, Provider, Facility, and so on) undergo further processing with the Match and Merge Services to create and/or update the Golden record, which is a set of tables representing the current state of the mastered subject.
Note: The output of the Match Service is a list of all affected Match Groups, defined as the set of instances that have been determined to represent the same Golden Instance.
The following diagram illustrates the process flow that is followed by the Process Subject subprocess.
Persist Instance
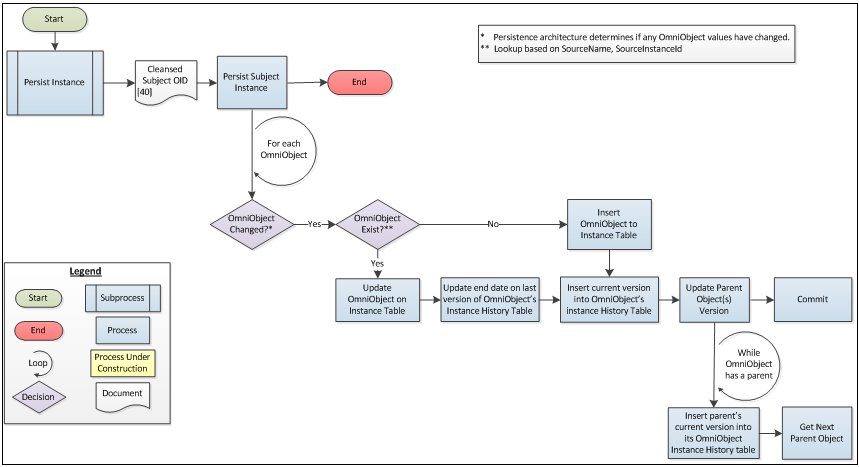
As stated earlier, the EMIR contains a table set to store the current state of each Subject Instance, as well as a history table equivalent, which stores row-level history for the Subject Instance tables.
Note: All code values stored on an instance reflect the value that came in from the Source System. Instance records do not store the standardized code value.
Omni-Patient has the following two requirements with regard to history tables:
- Omni-Patient must store a history record for each Object that has changed.
- Omni-Patient must store a history record for the Parents of each Object that has changed.
Note: A data change in one table does not necessarily result in a data change for all tables that make up the Subject Instance.
In order to satisfy the latter requirement, Omni-Patient stores a unique Transaction Id for each document that is processed. When a Table row is updated, its parent's Transaction Id is also modified, and a new history record is created for the parent. This behavior continues up the tree, but does not traverse back down to siblings.
Initial Load
|
Table |
ID |
Parent ID |
Txn ID |
Hist_StartDate |
Hist_EndDate |
|---|---|---|---|---|---|
|
Patient_hist |
Patient1 |
1 |
2013-01-01 |
||
|
Person_hist |
Person1 |
Patient1 |
1 |
2013-01-01 |
|
|
PersonName_hist |
PersonName1 |
Person1 |
1 |
2013-01-01 |
|
|
PersonIdentifier_hist |
PersonId1 |
Person1 |
1 |
2013-01-01 |
Update of PersonName
|
Table |
ID |
Parent ID |
Txn ID |
Hist_StartDate |
Hist_EndDate |
|---|---|---|---|---|---|
|
Patient_hist |
Patient1 |
1 |
2013-01-01 |
2013-02-01 |
|
|
Patient_hist |
Patient1 |
2 |
2013-02-01 |
||
|
Person_hist |
Person1 |
Patient1 |
1 |
2013-01-01 |
2013-02-01 |
|
Person_hist |
Person1 |
Patient1 |
2 |
2013-02-01 |
|
|
PersonName_hist |
PersonName1 |
Person1 |
1 |
2013-01-01 |
2013-02-01 |
|
PersonName_hist |
PersonName1 |
Person1 |
2 |
2013-02-01 |
|
|
PersonIdentifier_hist |
PersonId1 |
Person1 |
1 |
2013-01-01 |
Note: In the prior example where the update of the PersonName_hist table triggered an update for the Person_hist and Patient_hist tables, but did not update the PersonIdentifier_hist.
The following diagram illustrates the process flow that is followed by the Persist Instance process.
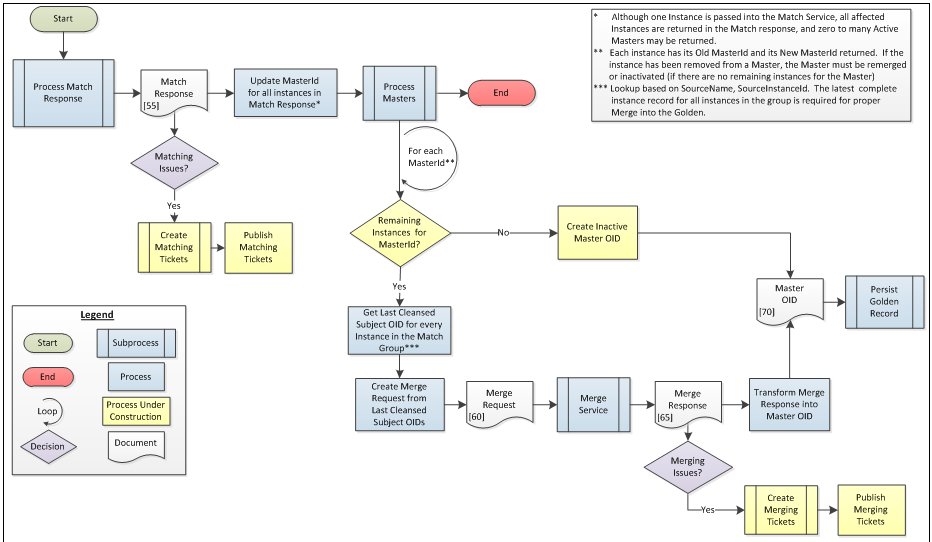
Process Match Response
After the set of Match Groups is returned by the Match Service on the Match Response, it must undergo further processing to create the merged Golden Record.
All Instances in the Match Group will be updated with the UEMID that represents that Match Group.
The last cleansed Subject OID is passed on the Merge Request for each instance in the Match Group.
The Merge Service will execute its rules against the set of Instances to determine the content of the Golden Record, and communicates this back to the Omni-Patient Server on the Merge Response.
Note: Depending on the configuration of the Merge Rules, changes to an instance in the Match Group may not always result in changes to the Golden record.
Omni-Patient creates a Master Subject OID for internal use in creating the Golden Record.
If any issues are incurred along the way, tickets are created and published to Advanced Remediation.
The following diagram illustrates the process flow that is followed by the Process Match Response process.
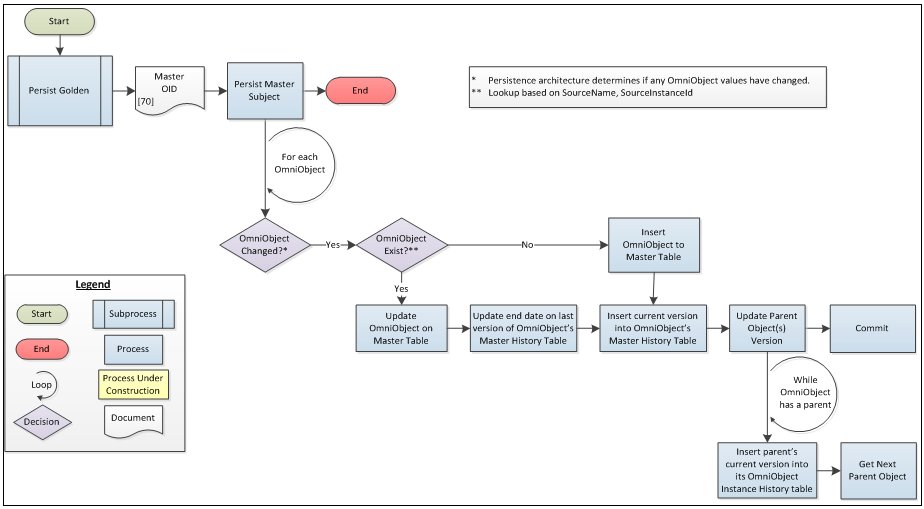
Persist Golden
Similarly to the Instance tables, the Master tables containing the Golden record also have a history table equivalent that stores row-level history for the Subject Master tables.
As stated earlier, the EMIR contains tables to store the current representation of the Subject Instance, as well as a history table equivalent that stores row-level history for the Subject Instance tables.
Note: All code values stored on a master reflect the Standardized code that was determined during the Code Standardization process. Master records do not generally store the value as passed by the SourceSystem.
The same history requirements that exist for the Instance, also exist for the Golden record.
- Omni-Patient must store a history record for each Object that has changed.
- Omni-Patient must store a history record for the Parents of each Object that has changed.
The following diagram illustrates the process flow that is followed by the Persist Golden process.