Database Usage
This section describes important information on database interactions and usage.
Bundle Deployment Tasks
The following deployment actions will affect the database structure and/or data content.
- Install/Replace (deploy-bundle-clean) - Wipeout existing database tables, install new bundle, create new schema.
- Update (deploy-bundle) - Upgrade an existing bundle, update Data Model.
- Update DQ Bundle (deploy-dq-bundle) - Replace the existing Data Quality/Mastering configuration files in /omnigen/OmniServer/Mastering, no database tasks.
- Reset (deploy-db-clean) - Reset the existing database to its default state from the command line or console. Options include Model Tables or Model and System Tables (everything).
Database Deployment Phases
- Drop
- Create/Update
The following table lists the command line (omni.sh/omni.cmd) deployment commands and their Omni Console equivalents.
|
Command Line |
Omni Console |
|---|---|
|
deploy-bundle |
Update bundle |
|
deploy-bundle-clean |
Install/Replace bundle |
|
deploy-db-clean |
Reset |
|
deploy-dq-bundle |
Update Data Quality bundle |
Database Reset and Clean
During a database reset or a deployment that invokes the clean flag, the following database tables are dropped and recreated. These table identifiers are hardcoded in the server and will match exact names or character patterns if denoted by an asterisk (*).
|
Omni-Gen Model Tables [Clean and Reset] |
|
|---|---|
|
Matched Patterns |
Specific Named Tables |
|
ids_* |
job_request |
|
md_* |
omni_error_docs |
|
og_* |
omni_remediation_ticket |
|
os_cdc_* |
omnigen_interface |
|
os_i* |
|
|
os_m* |
|
|
os_r* |
|
|
os_s* |
|
|
source_* |
|
|
repos_* |
|
|
Omni-Gen System Tables [Reset Only] |
|
|---|---|
|
Matched Patterns |
Specific Named Tables |
|
os_work_* |
|
Development is underway to begin separating system tables from bundle tables that are associated with a specific deployment, as their lifecycles are different. Separate lists are now maintained internally for tables that belong to each category. However, some ambiguity remains. For example, tables such as os_measure, which are system tables by definition, since they are not inherently tied to a subject model, have not been fully incorporated into the new lifecycle.
Order of Database Deployment Execution Tasks
These are performed after a new bundle is deployed or updated.
- Drop existing database tables (if clean is specified – Reset/Replace
only). This includes the following data sources:
- Workflow/Remediation (These are pre-written scripts, not generated dynamically.)
- Model (Version 3.6.1 includes OGC Grouping tables and sequences.)
- Mastering
- Ramp
- Source
- Clean system tables (Clean only). See Changes to System Tables Work Order and Work Order Item.
- System (Reset only). See Changes to System Tables Work Order and Work Order Item.
- Delete existing Liquibase Database changelogs.
- Custom(er) database pre-deployment migration scripts.
- Omni-Gen pre-deployment migration scripts.
- Create/Update database tables. This includes the following data
sources:
- Model (Version 3.6.1 includes OGC Grouping tables, sequences, and stored procedures.)
- Ramp
- Source
- Cohort
- System
- Workflow/Remediation (This is Create only. These are pre-written scripts, not generated dynamically from changelogs.)
- Custom(er) database post-deployment migration scripts.
- Omni-Gen post-deployment migration scripts.
Changes to System Tables Work Order and Work Order Item
The Work Order and Work Order Item (and other os* table measures, ramp, and so on) are created as part of the bundle deployment process.
- The Controller checks on startup to ensure the os_work_order and os_work_order_item tables exist. If not, it creates them.
- There will be two options for Database reset from the Console, see Deployment below.
- Deployment
- Install/Replace - If the tables exist, all Work Orders with omni_system_type = "SERVER", and their related Work Order Items, are deleted.
- Upgrade/Update - If the tables do not exist (for some reason) they are created or updated, as needed.
- Database Reset
- The Model option resets all managed tables as before, except Work Order and Work Order Item are handled as in Install/Replace.
- The System and Model option resets all of the managed tables in the system (including Work Order and Work Order Item). This is the same behavior as the previous implementation of Reset Database.
Database Validation Step
There is a validation step during installation that checks for the existence of the system tables in the database. After you supply parameters for the Omni-Gen database, you are prompted to continue or quit the installation, based on the existence of the tables. This serves to prevent you from accidently overwriting database table information.
Changes to the Lifecycle for Workflow/Remediation Tables for Version 3.5.1
- The Workflow/Remediation tables are no longer created during installation.
- There is no longer a screen in the installer that prompts about creating the Remediation database tables.
- The Controller checks on startup to ensure the Workflow/Remediation tables exist. If not, it creates them.
- Deployment
- Install/Replace - The Workflow tables are dropped or created, all data is lost.
- Upgrade/Update - Skipped.
- Database Reset - Same as Install/Replace.
Deployment Process Detail
Generating JPA from IDS, changelogs, and so on.
- Backup existing bundle.
- Clean previous bundle files and generated artifacts.
- Copy the bundle to your directory and unzip the contents.
- Copy any bootstrap OID files (OHD only).
- Generate Effective IDS documents.
- Generate IDS documentation.
- Generate IDS sample OIDs.
- Generate XSD schemas for the IDS documents.
- Generate JPA model for the IDS documents.
- Compile the JPA model.
- Weave the JPA model.
- Package and move the model jar.
- Copy the new DQ configurations for Cleansing, Merging, Matching, Remediation, and Relationships.
Deployment Logs
Each time a bundle or database deployment is undertaken from command line or UI, a log file is created with a name and timestamp corresponding to the event.
- The file name is created by concatenating the operation name and a timestamp of when the event started. Example: deploy_update_2017-11-06 12-25-29.865.json
- Location: omnigen/OmniGenData/deployment
- The information in these files is the content that is loaded on the deployment progress screen of the Omni Console.
The following table provides a list of the possible generated log files and the corresponding deployment commands.
|
Deployment Action |
File name |
|---|---|
|
Update bundle |
deploy_update_{timestamp}.json |
|
Install/Replace bundle |
deploy_install_{timestamp}.json |
|
Update DQ bundle |
deploy_dq_update_{timestamp}.json |
|
Reset database |
deploy_reset_{timestamp}.json |
Data Quality Bundle Deployments
Added an ability for Data Quality Only deployment bundles that skip all code generation/IDS operations and database processing. This will only replace the DQ configuration, and perform any DQ related operations.
The steps include copying the following configuration files from the exploded bundle:
- Cleansing
- Matching
- Merging
- Remediation
- Relationships
- Rebuilding the lookup sent with the bundle
This assumes that the IDS directory in the deployment bundle will be empty for a DQ only bundle.
Changes:
- Add deploy_dq_bundle command to the command line. This will bypass all the database processes normally run during deployment.
- Added an additional button to the Deployment screen on the Omni Console. There are now two options attached to the Update Bundle button. One for the standard Deployment bundle, and one for the Data Quality Bundle.
- New command line task deploy_dq_bundle to execute this action.
Database Migration
This process allows pre- and post-deployment database scripts to be run from separate locations for customers and the internal Omni-Gen team.
The following directory structure exists to hold the source files used in the migration process. There are pre and post folders that contain a directory for each data source. The migration scripts should be added to the appropriate directory.
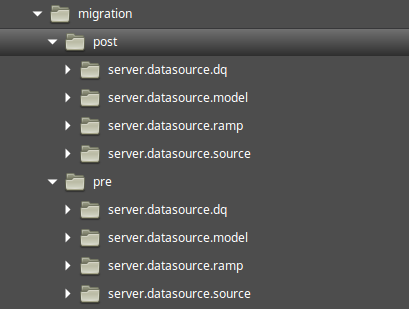
Customer: /omnigen/OmniGenData/migration
Omni-Gen: /omnigen/OmniServer/dbms/migration
Example of SQL wrapper for a Liquibase changelog:
- It is assumed that the end-user will be using this format, so the SQL syntax should be database vendor specific.
- This changeSet executes native SQL against the specified database (H2 in this case).
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<databaseChangeLog xmlns="http://www.liquibase.org/xml/ns/dbchangelog"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.liquibase.org/xml/ns/
dbchangelog http://www.liquibase.org/xml/ns/dbchangelog/dbchangelog-
3.3.xsd">
<changeSet author="liquibase-docs" id="sql-example">
<sql dbms="h2"
endDelimiter="\nGO"
splitStatements="true"
stripComments="true">
<comment>You must specify the Schema if it is not the
default for the datasource</comment>
<comment>This varies between databases</comment>
create table person(name varchar(255));
insert into person (name) values ('Bob');
</sql>
</changeSet>
</databaseChangeLog>If you are not using the default schema for a data source, it must be explicitly specified in the migration script as shown in the changelog comment above.
It is recommended to continue using the standard changeset format to accommodate as many database vendors as possible. However, there may be vendor specific issues where the SQL version is more appropriate.
Description of Database Tables
This section includes information on the database tables, as well as noted naming convention for the deployment specific tables.
- Liquibase:
- Holds transactions for all the operations performed by Liquibase on the given database.
- Databasechangelog, databasechangeloglock
- Ramp:
- Used to load data from the ramp into the Omni-Gen environment.
- Named: og_{subject_name}_r
- Source:
- Source data (does not get modified).
- Named: og_{subject_name}_s
- Instance:
- Instance data (Source data after Cleansing process, if any.)
- Named: og_{subject_name}
- Master:
- Holds the mastered records for a given subject.
- Named: og_{subject_name}_m
- History:
- Named: og_{subject_name}_h
- Work Flow:
- Holds information related to the remediation process.
- Named: wf{}
- System tables:
- Used by Omni-Gen system, not dependent on the model.
- Named: os_
Below is a list of Omni-Gen system tables. These are not subject specific and exist regardless of the subject deployment bundle.
System tables and descriptions – DO NOT MODIFY TABLES
|
System Table Name |
Description |
|---|---|
|
ids_override_match |
|
|
ids_override_property |
|
|
job_request |
|
|
md_ids_document |
|
|
md_ids_document_change |
|
|
md_ids_document_element |
|
|
md_ids_document_group |
|
|
md_ids_document_list |
|
|
md_ids_document_promote |
|
|
md_ids_document_type |
|
|
os_measure |
Measures (metrics/timings) for various processes across the Omni-Gen system. |
|
os_ramp_control |
Data loading jobs and related information that were submitted to the ramp for processing. |
|
os_reload_queue |
|
|
os_source_code_xref |
Source code cross-reference tables. |
|
os_subject_group |
Grouping |
|
os_subject_group_relation |
Grouping relation |
|
os_word_order |
Subject specific jobs to be processed by the system. |
|
os_work_order_item |
A detailed list of steps that are undertaken in each work order. |
|
Grouping Table Name |
Description |
|---|---|
|
os_subject_group |
Also listed in System table. |
|
os_subject_group_relation |
Also listed in System table. |
|
subject_group |
|
|
group_node |
|
Workflow Table Name |
Description |
|---|---|
|
scxml_instance |
|
|
scxml_lock |
|
|
wfCases |
|
|
wfDocument |
|
|
wfEvents |
|
|
wfMetaData |
|
|
wfPayload |
|
|
wfRemedyRef |
|
|
wfTicketLock |
|
|
wfTickets |
A list of remediation tickets to be resolved. |
|
workflow_version |
Metadata on the creation of Workflow Tables. |
|
case_doc_xref |
View |
|
wfUserCase |
View |
Data Quality tables – DO NOT MODIFY TABLES
|
System Table Name |
Description |
|---|---|
|
repos_{subject_name}_data |
|
|
repos_{subject_name}_form |
|
|
repos_{subject_name}_keys |
|
|
repos_{subject_name}_meta |
|
|
repos_{subject_name}_wdkey |
|
|
repos_{subject_name}_wgid |
|
|
repos_{subject_name}_wkey |
|
|
repos_{subject_name}_wpk |
Change Log Generation and Execution
The fundamental building block of Liquibase is the Changelog.
These are stored in omnigen/OmniServer/dbms/changelogs.
A set of changelogs is generated for each of the main data sources in the Omni-Gen system.
- MigrateChangeLog.xml
- A Liquibase changelog denoting the differential between the existing database and the generated JPA classes (Model Jar).
- DropChangeLog.xml
- A Liquibase changelog denoting the operations necessary to drop all of the specified tables in the given schema.
- JpaModel.xml
- A Liquibase changelog created directly from the JPA class definitions according to the persistence.xml.
|
Source |
omnigen-sourceMigrateChangeLog.xml |
|
omnigen-sourceDropChangeLog.xml |
|
|
omnigen-sourceJpaModelChangeLog.xml |
|
|
Ramp |
omnigen-rampMigrateChangeLog.xml |
|
omnigen-rampDropChangeLog.xml |
|
|
omnigen-rampJpaModelChangeLog.xml |
|
|
Model |
omnigen-modelMigrateChangeLog.xml |
|
omnigen-modelDropChangeLog.xml |
|
|
omnigen-modelJpaModelChangeLog.xml |
|
|
Mastering |
omnigen-masteringDropChangeLog.xml |
|
System |
omni-systemMigrateChangeLog.xml |
|
omni-systemJpaModelChangeLog.xml |
|
|
omni-systemDropChangeLog.xml |
|
|
Entire database schema |
{hashkey}-DatabaseChangeLog.xml |
Below are example subsets of the different changelogs.
DropChangeLog.xml
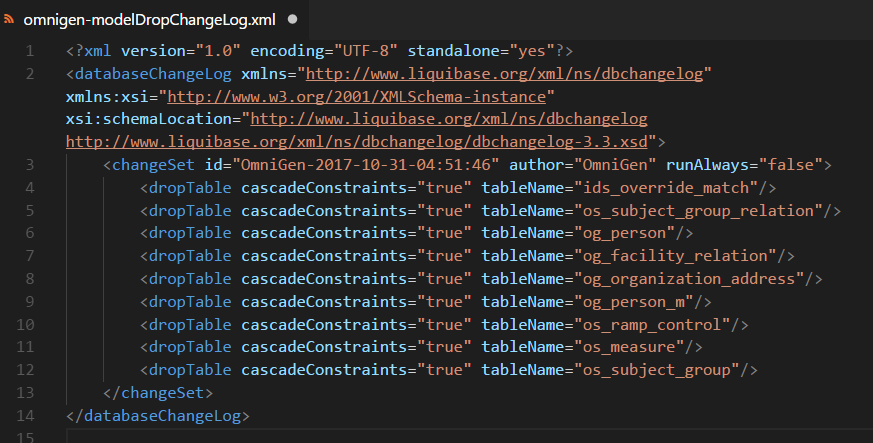
MigrateChangeLog.xml/JpaChangeLog.xml
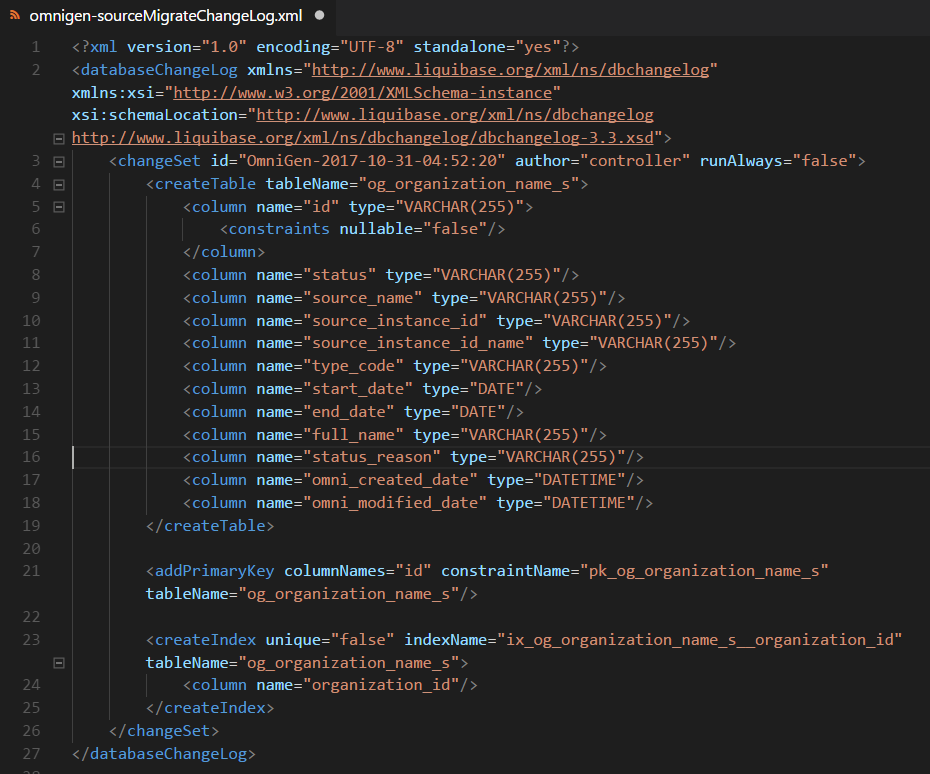
ChangeLog Locations
Omni-Gen Liquibase Changelogs are stored in the following locations, under omnigen/OmniServer/dbms/:
- Changelogs: All dynamically generated changelogs created by Omni-Gen during the deployment process. This folder gets cleared during a Reset or Bundle Clean operation.
- Controller: Pre-written Liquibase scripts that run during the startup phase of the Controller.
- Grouping:
- A Liquibase script that resets the subject_group and group_node tables related to grouping during a bundle reset or installation/replace.
- A Liquibase script to create the tables, sequence, and stored procedures during the update database phase of deployment.
- Migration:
- Contains pre-written database scripts to aid in migration between versions or feature releases. These run every time deployment is executed.
- Separate folders for each data source.
- Different location for Information Builders system and customer-specific scripts.
- System: Contains pre-written scripts related to System database table maintenance. Currently, this only includes cleaning Work Order and Work Order Item tables, and their creation.
OmniGenData and OmniGovConsole Data Remediation
- Liquibase: Contains the Drop and Create Liquibase scripts that run raw SQL statements, based on the type of database being used.
- Sql: Contains the raw SQL scripts to drop and create all necessary Workflow/Remediation tables for each database.
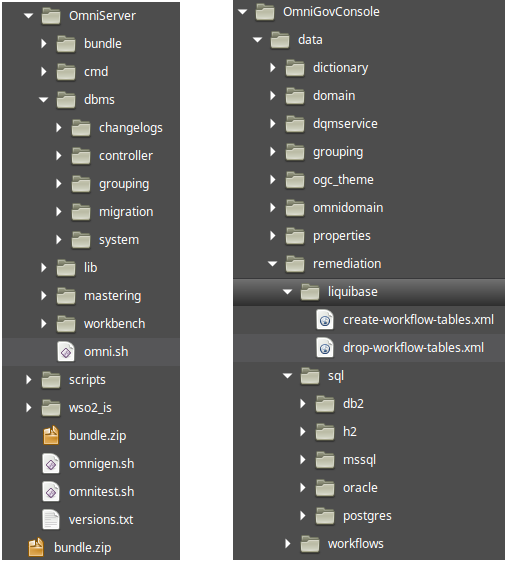
Controller Database Tasks
The Controller may execute a number of database operations, depending on the state of the system.
The root Liquibase script for the controller is stored in /OmniServer/dbms/controller. This script contains a list of scripts and files to execute that includes creating the Work Order, Work Order Item, and Workflow/Remediation tables, if they do not already exist. If any issues occur during this process, the Controller will continue to start, either by executing an empty Changeset, or ignoring the exception. A message will be included in the Controller log file indicating the issue, and the Console will show the relative configuration errors.
Console Database Connectivity Checks
The controller will validate all database connections at a set interval (every 20 seconds) and display an error regarding any issue, if one exists. You will be prohibited from taking any actions you would normally take with an invalid configuration. If the database reconnects or the settings are fixed, the errors will resolve and the console will return to normal.
Operations Console
The Operations pages on the Console provide a better idea of the inner workings of your Omni-Gen system. The database activity tab shows the slowest ten, and the most recent ten queries from the Server. This feature must be enabled from the Database/Configuration screens (Model, Ramp, Source) before data is run through the system in order to gather the metrics.
Database Pools and Connection Information
The Omni application makes use of multiple database connection pools to manage database connections. Each is separately configurable, but a mechanism is provided to allow common-configuration (across server and controller) using the 'default' settings. Configuration for controller and server can be changed in the OmniGenConfiguration.property file. Configuration for Tomcat is controlled in files found in OmniGovConsole/conf/Catalina.
- Settings: defaultDataSourceSettings
- Property Prefix: server.datasource.default
- Max-active: 50
- Initial Size: 2
Omni Controller Application
- Pool: modelConnectionPool
- Construction: Eager
- Settings: modelDataSourceSettings
- Property Prefix: server.datasource.model
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Controller Application
- Pool: systemConnectionPool
- Construction: Eager
- Settings: systemDataSourceSettings
- Property Prefix: server.datasource.system
- Max-active: 50
- Initial Size: 2
- Derives From: modelDataSourceSettings
Omni Server Application
- Pool: consumptionConnectionPool
- Construction: Lazy
- Settings: consumptionDataSourceSettings
- Property Prefix: server.datasource.consumption
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Server Application
- Pool: modelConnectionPool
- Construction: Lazy
- Settings: modelDataSourceSettings
- Property Prefix: server.datasource.model
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Server Application
- Pool: masteringConnectionPool
- Construction: Lazy
- Settings: masteringDataSourceSettings
- Property Prefix: server.datasource.dq
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Server Application
- Pool: rampConnectionPool
- Construction: Lazy
- Settings: rampDataSourceSettings
- Property Prefix: server.datasource.ramp
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Server Application
- Pool: sourceConnectionPool
- Construction: Lazy
- Settings: sourceDataSourceSettings
- Property Prefix: server.datasource.source
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Omni Server Application
- Pool: systemConnectionPool
- Construction: Eager
- Settings: modelDataSourceSettings
- Property Prefix: server.datasource.model
- Max-active: 50
- Initial Size: 2
- Derives From: defaultDataSourceSettings
Tomcat Application
- Pool: ogc.xml
- Construction: Eager
- Settings: grouping_config.db
- Max-active: 10
- Initial Size: 10
Tomcat Application
- Pool: OmniDomain.xml
- Construction: Eager
- Settings: jdbc/OmniWorkflow
- Max-active: 10
- Initial Size: 10
Tomcat Application
- Pool: OmniDomain.xml
- Construction: Eager
- Settings: jdbc/OmniGen
- Max-active: 10
- Initial Size: 10
Tomcat Application
- Pool: RemediationService.xml
- Construction: Eager
- Settings: jdbc/OmniWorkflow
- Max-active: 10
- Initial Size: 10
The following are descriptions of the database pools and connection information.
Application. The name of the Omni component that holds the pool.
Pool. The name of the JDBC pool. The pool name should be unique for each application and is not configurable. For Tomcat, this is the name of the file in conf/Catalina that configures the pool, and must coincide with the corresponding webapp.
Construction. Whether the pool is created at application startup (Eager), or is done when features needing the pool are activated (Lazy). Not configurable.
Settings. The name of the settings that govern the pool. For Tomcat, this is the Resource name.
Derives From. If a pool property is not provided, the corresponding value from this setting will be used.
Property Prefix. The property prefix to alter the settings in the OmniGenConfiguration.property file.
Max-active. The maximum number of active connections that can be allocated from this pool at the same time. For JDBC, if additional connections are requested, they will block waiting for a free connection, and may timeout if one does not become available within the timeout period. Max-active is configurable by setting a property of PROPERTY_PREFIX.max-connections (for example, server.datasource.default.max-connections). In Tomcat, it is configured by setting the maxActive property of the Resource.
Max-idle. The maximum number of connections that should be kept in the idle pool. In Tomcat, it is configured by setting the maxIdle property of the Resource.
Min-idle. The minimum number of connections that should be kept in the pool at all times. For JDBC, the default value for this property is derived from 'Initial Size'. In Tomcat, it is configured by setting the minIdle property of the Resource.
Initial Size. The number of connections that will be established when the connection pool is started. Initial Size is configurable by setting a property of PROPERTY_PREFIX.initial-connections (for example, server.datasource.default.initial-connections). In Tomcat, it is configured by setting the initialSize property of the Resource.
Ramifications: With all services running, a minimum of 56 connections would exist, and at most, 440 connections would be open. Using the default settings, it is recommended that a database support 500 maximum connections. This is configured differently for each database (PostgreSQL: the max_connections property in pg_hba.conf, Oracle: TBD, SQL-Server: TBD).
Liquibase
Source control for your database Liquibase is a software framework that provides a database vendor agnostic abstraction over common database operations. Utilizing the Changeset structure (differing formats are XML, JSON, YAML), you define database operations in a Liquibase specific format. When the changeset is executed, it will manage any idiosyncrasies under the hood for the specific database vendor (SQL Server, Oracle, Postgres, and so on).
http://www.liquibase.org/
Liquibase Notes: A version of Liquibase is being used that has been patched to address an issue. Deployment was failing against a SQL Server database with a case sensitive collation (for example, SQL_Latin1_General_CP1_CS_AS). It is version 3.5.3 available from Maven with an additional few commits.
Change tracking: There is a special table that is utilized by Liquibase for the management and record keeping of changelog actions called databasechangelog. It contains a hash of the designated changeset, as well as other identifying information. Once created, the Omni-Gen system will not reset this table, it must be manually dropped.
Fields contained in this table:
|
Column |
Standard Data Type |
Description |
|---|---|---|
|
ID |
VARCHAR(255) |
Value from the changeSet "id" attribute. |
|
AUTHOR |
VARCHAR(255) |
Value from the changeSet "author" attribute. |
|
FILENAME |
VARCHAR(255) |
Path to the changelog. This may be an absolute path or a relative path depending on how the changelog was passed to Liquibase. For best results, it should be a relative path. |
|
DATEEXECUTED |
DATETIME |
Date/time of when the changeSet was executed. Used with ORDEREXECUTED to determine rollback order. |
|
ORDEREXECUTED |
INT |
Order that the changeSets were executed. Used in addition to DATEEXECUTED to ensure order is correct even when the databases datetime supports poor resolution. Note: The values are only guaranteed to be increasing within an individual update run. There are times where they will restart at zero. |
|
EXECTYPE |
VARCHAR(10) |
Description of how the changeSet was executed. Possible values include "EXECUTED", "FAILED", "SKIPPED", "RERAN", and "MARK_RAN", |
|
MD5SUM |
VARCHAR(35) |
Checksum of the changeSet when it was executed. Used on each run to ensure there have been no unexpected changes to changeSet in the changelog file. |
|
DESCRIPTION |
VARCHAR(255) |
Short auto-generated human readable description of changeSet. |
|
COMMENTS |
VARCHAR(255) |
Value from the changeSet "comment" attribute. |
|
TAG |
VARCHAR(255) |
Tracks which changeSets correspond to tag operations. |
|
LIQUIBASE |
VARCHAR(20) |
Version of Liquibase used to execute the changeSet. |
Database Locking: Liquibase uses a distributed locking system to only allow one process to update the database at a time. The other processes will simply wait until the lock has been released. There is as special table created for this purpose called databasechangeloglock.
Fields contained in this table
|
Column |
Standard Data Type |
Description |
|---|---|---|
|
ID |
INT |
Id of the lock. Currently there is only one lock, but is available for future use. |
|
LOCKED |
INT |
Set to "1" if the Liquibase is running against this database. Otherwise set to "0". |
|
LOCKGRANTED |
DATETIME |
Date and time that the lock was granted. |
|
LOCKEDBY |
VARCHAR(255) |
Human-readable description of who the lock was granted to. |
Common Database Considerations
SQL Server
- All indexes are explicitly created as non-clustered. This was requested as a performance enhancement. By default, SQL Server will create a clustered index on the primary key, unless instructed otherwise.
- File locks are common.
- Limit to the length of indexes across columns (900 characters for releases prior to SQL Server 2016, 1700 for SQL Server 2016 and higher).
- No Drop with Cascade.
- Maximum object name is 100 characters.
Oracle
- Limit to the length of indexes across columns.
- Maximum object name is 30 characters.
- No Drop with Cascade.
PostgreSQL
- Maximum object name is 63 characters.
H2
- This is used as the default by Omni-Gen if the system cannot configure a connection to an external database.
Db2
- No Drop with Cascade.
- To use Db2 as a repository database, the following tuning steps are required. This is due to the nature of Db2 and its requirement
for higher memory consumption during the deployment phase. If the memory is not increased, you might encounter an OutOfMemoryError exception when resetting the environment or the deployment phase.
For new installations:
- The Db2 JDBC URL should include a traceLevel=0 option during the configuration.
- Prior to running config on the binary, set cfg.server.commandline.max-memory=2048M in the configuration file.
- After config completes, verify server.commandline.max-memory=2048M in the OmniGenconfiguration.properties file.
For existing installations:
- The Db2 JDBC URL should include a traceLevel=0 option during the configuration.
- In the Omni Console, navigate to Configuration, Runtime, and click the Command Line tab. Set the JVM Process Max Memory parameter to 2048M.
- Stop all processes and then restart.
Performance Tuning
When handling a large number of records, you may want to optimize the database being used for Omni-Gen. One way to tune the performance of the database is to increase the amount of available memory. For example, for one million records, increasing the memory by 2GB could improve performance.
In addition, removing the following indexes can also improve performance:
- REPOS_SUBJECT_WGID
- REPOS_SUBJECT_WPK
where:
- SUBJECT
-
Is the customer subject.