OnRamp Operational Details
|
Topics: |
This section describes the OnRamp operational details.
Ramp Quality Gate
As of Version 3.14, the Ramp Quality Gate service creates a QUALITY_GATE work order which flags erroneous records in a ramp batch, so they are not included in Omni-Gen work order processing. A new column, rec_quality, on the _r tables captures the error and warning status detected by the Quality Gate.
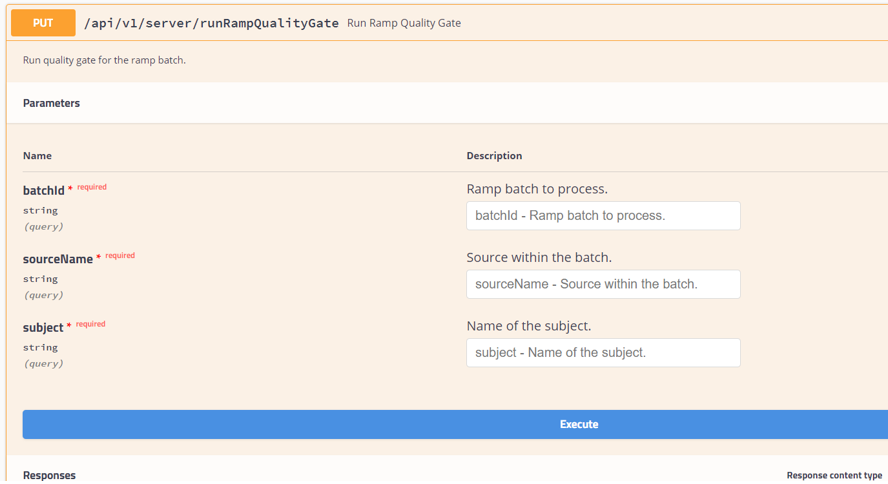
The service has the following three parameters, all of which are required:
- batchId
- sourceName
- subject
The QUALITY_GATE work order does the following:
- Scans all ramp tables of a subject.
- Generates system warnings for columns that require trimming.
- Generates system errors for columns that contain embedded white spaces or a colon (:).
- Updates the rec_quality column on the ramp record. If the record generated system errors, rec_quality = 'E'. If the record generated system warnings, rec_quality = 'W'.
Note: The measures of this work order show three values:
- Number of the records scanned (Processed).
- Number of the records that did not generate a system error (Results).
- Number of the records that generated a system error (Errors).
When the work order completes, click the System Messages menu item on the work order to see the warnings and errors.
At this time, all flagged records should be fixed, and the rec_quality column should be set to NULL before the batch is submitted for processing. This applies even to those records marked with a warning, because NATIVE_SQL loads can only trim spaces.
The following image shows an example of the parameters for Ramp Quality Gate.
Parallelism
The Relational OnRamp will process batches for different top-level subjects concurrently. Multiple batches for the same top-level subject will be processed serially unless Parallel Processing is enabled.
Launching Relational OnRamp Batches
Omni-Gen supports the following methods of launching an OnRamp batch:
- Directly updating os_ramp_control.
- Calling the ProcessRamp web service.
Directly Updating os_ramp_control
You can add a row to os_ramp_control, setting the following columns.
- batch_id (string). Batch to execute.
- subject (string). Subject to process as part of the batch.
- source_name (string). Restrict the impact of the load to records of a specific source system.
- batch_type (string). Processing mode. [UPSERT, INSERT_ONLY, REPLACE_SELECTED, REPLACE_ALL, DELETE]
- batch_options (string). Deprecated. Use data_transfer_mode, change_detection, upsert_null_handling, and truncate_before_insert columns, instead.
- load_type (string). Deprecated.
- data_transfer_mode (string). [JPA, NATIVE_SQL]. JPA - database neutral, NATIVE_SQL - high-performance database specific. Applies to SQL Server and PostgreSQL only.
- change_detection (string). [ENFORCE, IGNORE]. ENFORCE - identifies business duplicates and suppresses them from further processing. IGNORE - all records in batch are fully processed (including duplicates). Useful for error recovery.
- upsert_null_handling (string). [PRESERVE, OVERRIDE]. Governs how to handle missing values on an update (replaces deprecated batch options PRESERVE_ON_NULL and OVERRIDE_ON_NULL). Applies to UPSERT only.
- truncate_before_insert (string). [FALSE, TRUE]. Applies to INSERT_ONLY mode only. Truncate data before an INSERT_ONLY operation.
- state (string). Set to READY when batch is fully assembled.
- active (string). Set to Y to enable the subject/batch to be loaded.
The os_ramp_control can be monitored to follow the status of a ramp batch.
The following are possible values of the state field:
- PENDING. Indicates the ramp will begin loading.
- LOADING. Indicates the ramp is being loaded.
- READY. Load complete and ready for processing.
- SCHEDULED. Schedules for processing.
- PROCESSING. Omni-Gen is currently processing the subject batch.
- COMPLETE. Omni-Gen completed processing of the subject batch.
- FAILED. Processing of the batch has failed.
Note: This information is also available in the RampControl section of the Omni Console.
Invoking the ProcessRamp Web Service
This section describes the ProcessRamp web services that can be used to launch a ramp batch.
V4 Web Service
https://server_host:server_port/server/api/v1/server/processRamp.v4
The HTTP PUT request accepts the parameters listed and described in the following table.
|
Parameter |
Type |
Description and Values |
|---|---|---|
|
batchId |
string |
Batch to execute. |
|
subject |
string |
Subject to process as part of the batch. |
|
sourceName |
string |
Restrict the source system to participate in the batch. |
|
batchType |
string |
Mode corresponding to the batch_type:
|
The following table provides the batch options (sub directives) for the process ramp service and the corresponding batch_options column in os_ramp_control.
|
Name |
Type |
Description and Values |
|---|---|---|
|
dataTransferMode |
string |
Overrides the default data transfer mode runtime configuration setting.
Note: NATIVE_SQL generates a runtime error for unsupported databases. For information on the Batch Split Size setting, see Batch Split. |
|
changeDetection |
string |
Determines whether or not to eliminate duplicates from further processing (data quality operations).
Note: ChangeDetection = IGNORE replaces batch option FORCE_REPROCESS. |
|
upsertNullHandling (previously addUpdateNullHandling) |
string |
UPSERT only. Governs how to handle missing values on an update.
|
|
truncateBeforeInsert |
boolean |
Truncate data before an INSERT_ONLY operation. Used for a full replacement of the data set. Applies only to transactional subjects.
Note: Is an error unless loadType is INSERT_ONLY. |
Batch Split
As of Version 3.14, the Batch Split feature allows for more optimized database resource usage and for the progress of the load to be visible to the user.
This is only applicable to loads of a transactional subject, where the Data Transfer Mode is NATIVE_SQL. In addition, the batch process must be bound to a single source
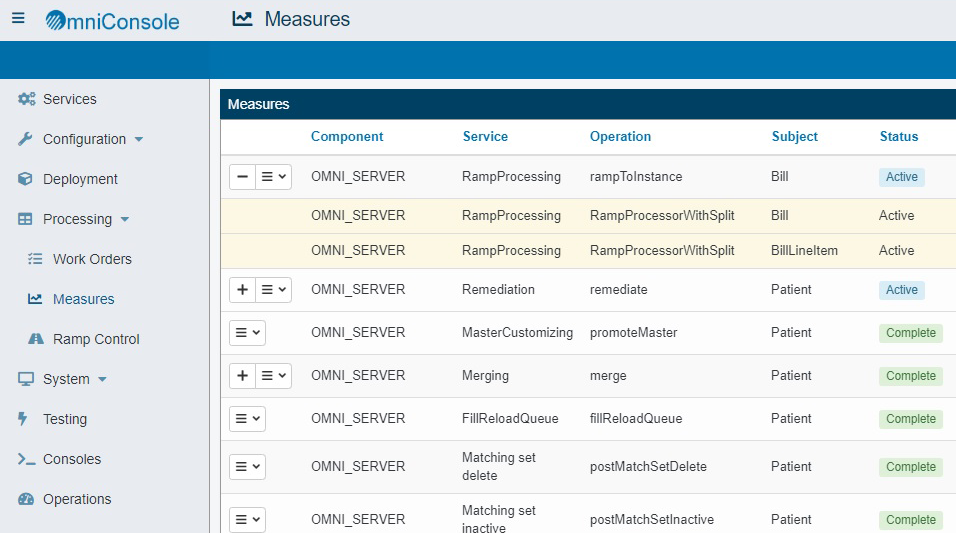
If the set of instances in a work order is too large, resource constraints can result in a batch processing failure. Using the Batch Split Size setting, multiple NATIVE_SQL operations are executed, each targeting a subset of the batch. The Measures are updated when each operation completes, showing how many records were processed and how many records were new or updated.
When Batch Split is off, all the records in the batch are processed by a single NATIVE_SQL operation and the measures are only updated when the operation is complete.
The default value of Batch Split Size is -1, which means not to process in chunks. If this value is greater than 0, the batch will be processed in Batch Split Size chunks. For example, if there are 10 million records in the table and the size is set to 1 million, approximately one million rows will be processed at a time.
The following image shows the measures updating while ramp to instance is processing. This only happens with Batch Split. Otherwise, measures are updated once they are completed.