Catch Service (com.ibi.agents.XDCatchAgent)
Syntax:
com.ibi.agents.XDCatchAgent
iIT Service Object:
operations: Catch errors in flows
Description:
Error handling in iWay Service Manager (iSM) process flows can be accomplished in a number of different ways. Supported method and techniques include:
- Explicitly checking for an error, post-service execution, by conditioning the edge with onError or onFailure.
- Including an outlet conditioned with _iserror().
- Including a Catch service at the beginning of the channel. This channel has two edges on the output side that are used for processing. The first is the onCompletion edge. The second is the onCustom edge, with the onError and onFailure cases selected.
The concept of the Catch service is similar to a try-catch block in other programming languages.
In other programming languages, a block of code is enclosed between the braces of a try statement. Following the try block is a catch block of code that is enclosed in braces. The code in the catch block has statements that handle any errors that might occur in the try block.
When the thread of execution starts, each line in the try block of code is executed. If each statement is successful, execution continues at the statement following the closing brace of the catch block (assuming that there is not a finally block). If an error occurs within the try block, the thread of execution jumps to the code inside the catch block.
In a process flow, you can add a Catch node in front of the services in which an error might occur. There are five edges off this service:
- onCompletion
- onCustom
- onSuccess
- onError
- onFailure
The completion edge is the thread of execution in which everything works in a perfect scenario. All the edges after the service connected by the onCompletion edge are then connected to the onSuccess edge.
The onCustom edge has three selected cases (onError, onFailure, and error_retry). Any errors or failures that occur within the path of the process flow are directed down the onError and onFailure edge. The logic in this branch contains any services necessary to handle errors. The error_retry edge is followed when there is a retry exception. For example, when a SQL Object contains an invalid URL in the process flow, the onCustom/error_retry edge will be followed.
Think of the onCompletion path as the try block and the onCustom edge as the catch block.
You can add multiple Catch nodes in a process flow. The error branch is taken off the closest Catch node previous to where the error occurred. In this manner, you can add multiple error conditions for a given process flow if required.
The catch is hierarchical and each catch is considered nested in the prior Catch node. When a Catch node is triggered, the Special Register (SREG) iway.catchname is set to the name of the Catch node that first catches the error. The register is not replaced as succeeding Catch nodes see the error. This allows higher scopes to ascertain the scope under which the original error is caught. For example, if Task3 fails and the error is caught by CatchScope3, the register will be set to CatchScope3 even though the error may cascade through higher scopes.
Parameters:
|
Parameter |
Description |
|---|---|
|
Maximum Errors |
The maximum number of times a Catch will be effected per forward entry. |
The Catch facility can also be configured to allow only a specified count of catches. This helps to deal with errors in the error handler reached through the catch itself. For example, consider what happens in the process flow shown in Example 2 if the Write Error node fails. In this case, because the Write Error node does not itself provide an OnFailure edge and handle the failure, the failure is propagated upward, where it reaches the Catch node. That node passes the error down its failure edge, back to the Write Error node, which might again fail. If this continues, a loop situation arises.
The Maximum Errors parameter allows a count of the number of times a Catch node will pass the error to an error handler (the default value is three). If the number of errors reaching the Catch node exceeds this specified count, then the Catch node does not handle the error, but rather allows the error to be propagated upward to the next higher Catch node, or (if none is encountered) terminates the process flow.
The count is reset each time a document passes through the Catch node in the forward direction, so that the catch count applies only to the specific error handling situation.
It is possible to use this facility to add logic to the error handler itself. For example, you may want to apply error handing for up to six times, but only every five seconds. Doing so would provide an external system with time to accept the error. In this case, you might set the Maximum Errors parameter to six, and add a five second delay (using a Document Copy Service, XDCopyAgent) into the error handler logic before attempting to deal with the error.
Example 1
In this example, consider a process flow in where three tasks are performed serially (called Task1, Task2, and Task3). The process flow performs three tasks, as shown in the following image.
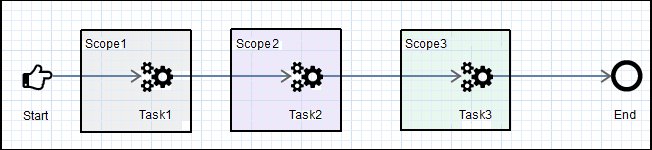
There is a requirement to handle errors in each task separately. So in our updated process flow, a Catch node precedes each Task node to handle errors in that task.
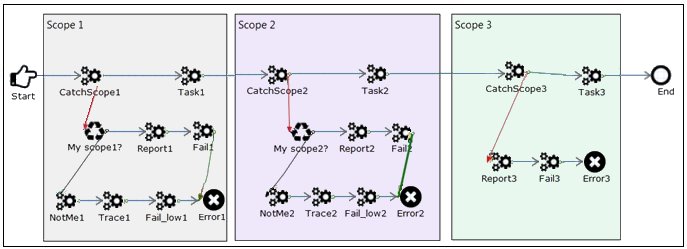
In this example, assume Report1 to Report3 are each an SQL object recording failures. If Task3 (on the main line of the process flow) fails, then the failure is caught by CatchScope3. Report3 records the failure and control passes to Fail3. Fail3 is a Fail service, which has a Bypass Catch Processing parameter set to true. For more information on the Fail service, see Fail Service (com.ibi.agents.XDFailAgent).
However, if Report3 fails, then the failure will be caught by CatchScope2. The Catch node for scope three does not catch the Report3 failure as it has already caught a failure. The scope in this example tests to determine whether the failure was in its scope, in which case Report2 will record the failure within the scope, or in a lower scope. It does this by the NotMe2 test, which evaluates the scope. This is a test node, which is set to the following parameter values:
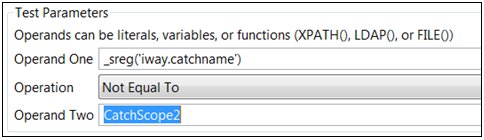
This causes the extra report to be bypassed. In this case, or example uses a Trace service (Trace1, Trace2) to report the error in the lower scope to a simple trace message. Following the trace message reporting a failure in a lower scope, the process flow uses a Fail service to issue the fail that did not get issued in the lower scope. This maintains the statistics of the channel.
In the multiple Catch node use case, setting the Bypass Catch Processing parameter of the Fail node to true will cause the failure request to bypass upper-level Catch nodes, avoiding the need for scope testing (such as with the example in the My Scope tests in upper scopes).
Example 2
In this example, a file is put into a directory after its creation from a previous channel. The sample process flow is responsible for transmitting the file to the customer FTP site.
Since this is an FTP site, it is subject to network and site availability and other possible outside issues. An error handling strategy is required so that none of the documents being processed are lost because of an outside issue.
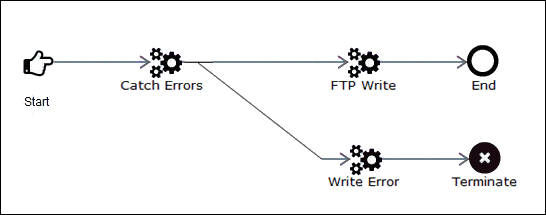
In process flow, the Catch node immediately follows the Start block. An onCompletion edge connects the Catch Errors block to the FTP Write block. The FTP Write block is an FTP emitter that is set up to write the file to an FTP site. The service directly following the XDCatchAgent (Catch Errors) must have an onCompletion edge for this to work correctly.
Following the FTP Write block is the End block. The edge connecting these two services is an onSuccess edge. If a different edge were used and an error occurred, the error edge off of Catch Errors may not be executed.
The onCustom edge of Catch Errors has the onError and onFailure cases selected for the properties. This edge leads to a file write service, Write Error, that puts the file into a hold directory for later reprocessing. Following Write Error, there is an End with a Terminate since no further processing is required at this point. In a real world scenario, a requirement might be that an email is sent if the site is down.
When the target FTP site is up and available, the files are written to the FTP site. If the FTP site is down or you cannot connect to it, the FTP write service will generate an error. This error causes the next execution point to be the File Write to save the file for further processing.