Configuring a Connection to a Hadoop Distributed File System Server
|
How to: |
The wrangler is a bridge between unstructured Hadoop Distributed File System (HDFS) data and structured or defined data sources. Before you create a wrangler configuration, you must ensure that a connection a HDFS server is available.
HDFS is a distributed file-system that stores data on commodity machines, providing very high aggregate bandwidth across the cluster.
Note: Wranglers are a non-Pipeline type of data configuration.
Procedure: How to Configure a Connection to a HDFS Server
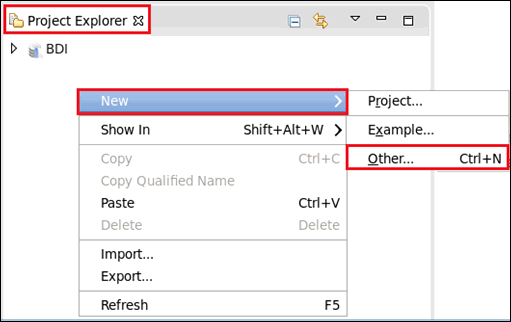
- Right-click anywhere within the Project
Explorer tab, select New, and then click Other from
the context menu, as shown in the following image.
You can also click the following icon on the toolbar:

The New dialog opens, as shown in the following image.
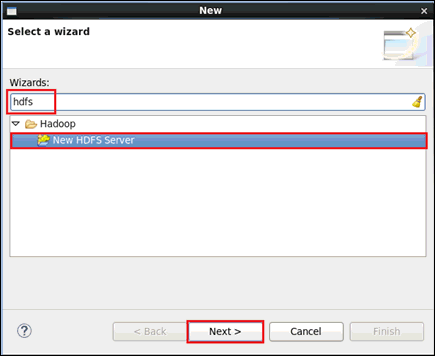
- Type hdfs in the field to filter
the selection, select New HDFS Server, and
then click Next.
The HDFS Server Location pane opens, as shown in the following image.
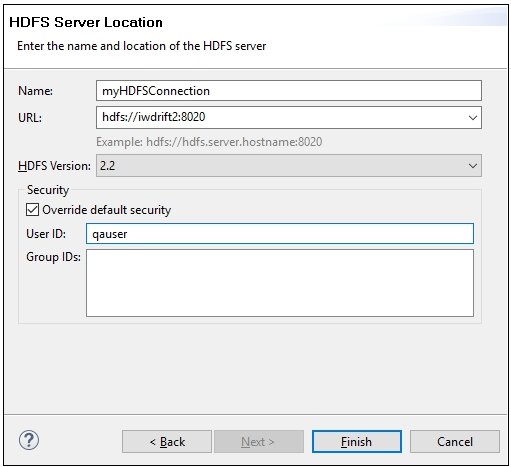
- Specify the following information:
- Name: Enter a name for the HDFS connection.
- URL: Enter an HDFS connection URL with a port number. This is usually the URL of the system in the cluster running the Hadoop server.
- HDFS Version: Select a HDFS version from the drop-down list.
- Security: Enter an explicit user ID, group IDs, or leave
blank for the default security implementation.
For more information on user identity and usage, see the Hadoop Distributed File System Permissions Guide.
- Click Finish.
Your new connection to a HDFS server is listed as a new node in the Project Explorer tab.