Creating and Executing a Sqoop Configuration
|
How to: |
Apache Sqoop is designed for bulk data input from structured data sources, such as relational databases, into a HDFS. Sqoop reads records row by row in parallel and writes them in the selected file format into a HDFS. Sqoop usually splits by the primary key, or a defined primary key if no primary key is present.
Note: Sqoops are a non-Pipeline type of data configuration.
Procedure: How to Create a Sqoop Configuration
- Expand an available iBDI project node
in the Project Explorer tab, right-click the Sqoops folder,
select New, and then click Other from
the context menu.
The New dialog opens, as shown in the following image.
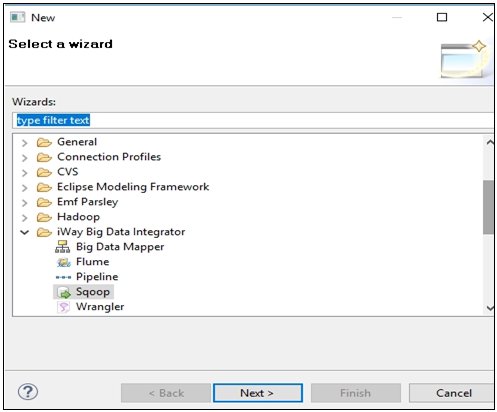
- Type sqoop in the field to filter the selection,
select Sqoop, and then click Next.
The New Sqoop dialog opens.
- Type a name for the new Sqoop in the Name field (for
example, mysqoop) and click Finish.
The Sqoop opens as a new tab (mysqoop.sqoop) in the iBDI workspace, as shown in the following image.
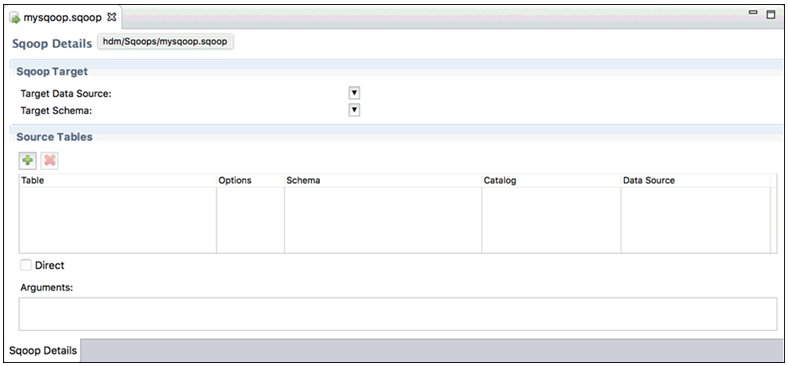
- From the Target Data Source drop-down list, select an
available Hive connection.

- From the Target Schema drop-down list, select the schema into which your data will be imported.
- Click Add (the green plus sign
icon) to select the table(s) you want to import.
To remove a table, select the table and then click Delete (the red X icon).
Note: If no database connections have been defined, these fields will appear empty. Go to the Data Source Explorer pane and define the connections to the source and target. Close and then open the Sqoop tab to continue.
More than one table can be selected, as shown in the following image.
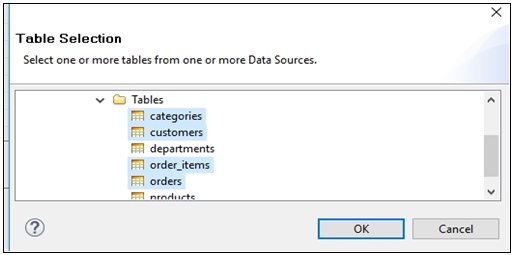
- Select the required table(s) and click OK.
The selected tables are now populated in the Source Tables area, as shown in the following image.
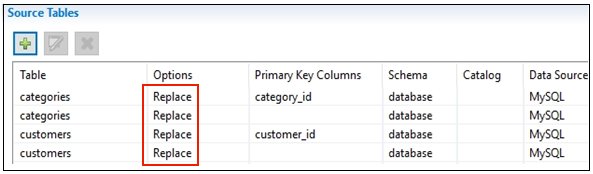
The following table lists and describes the available setting you can select for each table in the Options column.
Option
Description
Replace
Replaces the data if it already exists in the HDFS and Hive. Subsequent Sqoops of the same table will replace the data.
CDC
A key feature in iBDI, which executes Change Data Capture (CDC) logic. This means that subsequent executions of this Sqoop configuration will append only changes to the data. Two extra columns are added to the target table that enables CDC:
- rec_ch. Contains the hashed value of the record.
- rec_modified_tsp. Is the timestamp of when the record was appended.
Native
Allows advanced users to specify their own Sqoop options.
- Click the Save icon or use the
Ctrl+S shortcut to save your work.
Procedure: How to Execute a Sqoop Configuration
Once you have created a Sqoop configuration, a Sqoop file with a .sqoop extension is added to your Sqoops directory in your iWay Big Data Integrator (iBDI) project.
For more information, see Defining Run Configurations.