Using the Pipeline Builder
|
Topics: |
This section describes how to configure pipelines using the Pipeline Builder in iWay Big Data Integrator (iBDI).
Opening the Pipeline Builder
To open the Pipeline Builder, expand an available iBDI project node in the Project Explorer tab, right-click the Pipelines folder, select New, and then click Other from the context menu, as shown in the following image.
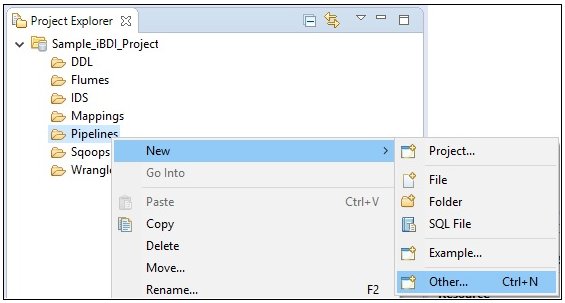
The New dialog opens.
Type pipeline in the field to filter the selection, select Pipeline, and then click Next.
You can also expand the iWay Big Data Integrator node in the New dialog and select Pipeline.
The Pipeline Builder can also be opened directly from the toolbar by clicking the Pipeline Builder icon. If you double-click an existing pipeline in the Pipelines folder (for example, pipe1.pipeline), the Pipeline Builder opens with the selected pipeline for editing.
The Pipeline Builder has two panes, as shown in the following image.

The left pane manipulates pipeline stages and the right pane displays parameters for the current stage, if that stage contains parameters.
Adding, Deleting, and Modifying a Stage
A new stage can be added to a pipeline by right-clicking on a stage and selecting New Sibling from the context menu or clicking the green plus (+) icon, as shown in the following image.
To delete a stage, click the red x icon, as shown in the following image.
The Source and Target stages cannot be deleted, they are required elements of a pipeline.
Pipeline stages can be added, deleted, or modified using the Component pane. Click on a Compute node to move it up or down in the sequence.
Adding, Deleting, and Modifying a Source
Add a source by clicking on a source entry in the left pane, then click change type in the right pane, as shown in the following image.
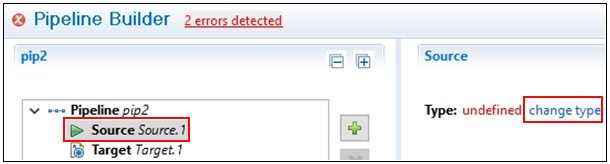
The Modify Source type dialog opens, as shown in the following image.
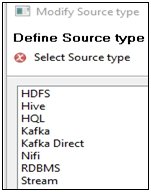
Select one of the available source types and then click Finish to continue. The right pane automatically opens the parameter view of the selected source type. For example, the following image shows RDBMS defined as a source type.
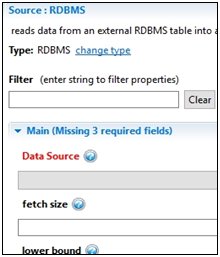
Using the Problems Pane
The Problems pane (or tab) in the lower part of the main window shows problems with the current pipeline. The status is changed when you click Save or Save All, as shown in the following image.

The following image shows the Problems pane before a pipeline source is configured:
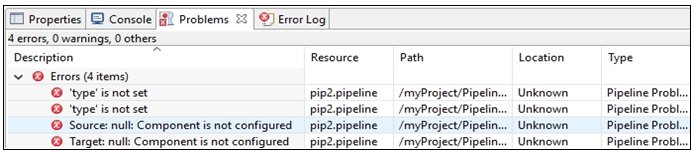
The following image shows the Problems pane after a pipeline source is configured:

Click the Save icon, File and then Save from the main menu, or press Ctrl+S. The pipeline status is updated, so Source is not indicated as having a problem status.
Chaining Pipelines
Pipeline chains can be constructed by using the Target of one pipeline (for example, a Hive table) as the Source for another pipeline. One key advantage of pipeline chains is the ability to repeat processing stages in a controlled manner to a data set.
Troubleshooting Pipelines
Pipeline stages do not have dependencies on other pipeline stages. Many operations return a new DataFrame or a table. If one stage ends with an exception, then the entire pipeline stops processing.
In many cases, an error in a pipeline stage can be corrected and the pipeline can be run again from the start, but if an earlier pipeline stage persisted data to Hive or a similar operation, then the pipeline cannot be restarted from the beginning without duplication of data.
Recommended Technique
For deployed jobs, review the Console log for the pipeline in question. In the following example, the column used in an OrderBy stage does not exist in the Source:
11/23/2016 10:43:17.333 [INFO] Exception in thread "main" org.apache.spark.sql.AnalysisException: Cannot resolve column name "sample_column" among (department_id, department_name);
Corrective Action
Open and edit the pipeline in the Pipeline Builder. Open the Compute Stage in question and change the column name to one matching the columns in the table. Save the pipeline, then use the Run Configurations facility to run the pipeline again.
If the pipeline is run with a CRON job or script, then review the exception log on the edge node to find the error.
Jobs can fail as a result of user error, disk error, system error, network error, or other types of errors. If the data is important, ensure that you always have a recovery or backup plan in case of issues.